Mời bạn thưởng thức Newsletter #97.
Why we’re rethinking cache for the AI era
Cloudflare chỉ ra rằng 32% lưu lượng mạng hiện nay đến từ các nguồn tự động, với AI bot đã vượt mốc 10 tỷ request mỗi tuần. Sự bùng nổ này tạo ra xung đột rõ rệt: các website buộc phải lựa chọn giữa tối ưu cho AI crawler hay cho người dùng thật, bởi hai nhóm có mẫu truy cập hoàn toàn khác nhau. AI crawler thường truy cập các URL độc nhất với tỷ lệ 70–100%, khám phá nội dung sâu và đa dạng (tài liệu, mã nguồn, media), đồng thời không duy trì session như người dùng nên mỗi instance bị tính như một khách riêng biệt. Hệ quả là tỷ lệ cache miss tăng vọt, khiến các kỹ thuật tối ưu truyền thống như prefetching trở nên kém hiệu quả. Wikipedia ghi nhận băng thông multimedia tăng 50%, Read the Docs, Fedora và Diaspora đều gặp tình trạng chậm dịch vụ vì crawler tải lặp lại các file lớn.
Để xử lý, Cloudflare đề xuất hướng ngắn hạn là thay thế thuật toán LRU bằng SIEVE hoặc S3FIFO, kết hợp caching dựa trên machine learning và bộ lọc traffic nhận biết AI. Về dài hạn, họ hướng tới kiến trúc cache phân tầng riêng biệt: edge cache ưu tiên tốc độ cho người dùng, tầng cache vừa phải cho các tác vụ AI nhạy cảm độ trễ như RAG hoặc summarization, và tầng cache sâu hơn, chậm hơn dành cho workload huấn luyện mô hình.
Điểm chính:
- 32% lưu lượng mạng đến từ nguồn tự động, AI bot tạo hơn 10 tỷ request mỗi tuần.
- AI crawler có tỷ lệ URL độc nhất 70–100%, phá vỡ hiệu quả của cache truyền thống.
- Các thuật toán mới như SIEVE và S3FIFO có thể thay thế LRU để giảm cache miss.
- Kiến trúc tương lai cần tách riêng cache cho người dùng và từng loại workload AI.
- Không duy trì session khiến mỗi crawler instance bị xem như khách riêng, làm nhiễu thống kê.
A Behind-the-Scenes Look at How We Release the Spotify App (Part 1)
Spotify chia sẻ cách đội ngũ Release vận hành quy trình phát hành ứng dụng hàng tuần cho hơn 675 triệu người dùng trên iOS và Android. Release Manager vừa đóng vai trò điều phối giữa các feature team, vừa xây dựng hệ thống công cụ hỗ trợ toàn bộ pipeline phát hành, với mục tiêu cân bằng giữa tốc độ ra mắt và chất lượng. Chu kỳ phát hành kéo dài hai tuần: tuần đầu dành cho phát triển, chạy nightly build và phân phối cho alpha user; đến thứ Sáu tuần thứ hai code được cắt nhánh, chuyển sang beta test và kiểm thử hồi quy thủ công; cuối tuần và thứ Hai là giai đoạn ổn định, submit lên app store; thứ Ba và thứ Tư triển khai theo từng giai đoạn từ 1% lên 100% người dùng.
Trước khi submit, mỗi bản phát hành phải vượt qua các cổng chất lượng nghiêm ngặt: toàn bộ commit pass kiểm thử tự động, không còn bug chặn, các team ký duyệt, tỷ lệ crash dưới ngưỡng cho phép và đủ dữ liệu kiểm thử về content consumption. Để giảm rủi ro, các tính năng lớn như Audiobooks trong bản 8.9.2 được lên lịch phát hành riêng để tập trung kiểm thử, feature flag cho phép team merge code an toàn mà chưa bật cho người dùng, còn giai đoạn rollout 1% ban đầu giúp phát hiện sự cố nghiêm trọng sớm. Kết quả: khoảng 95% phiên bản kế hoạch được phát hành thành công tới toàn bộ người dùng mỗi tuần.
Điểm chính:
- Chu kỳ phát hành hai tuần với nightly build, beta test và rollout theo phần trăm.
- Cổng chất lượng gồm kiểm thử tự động, zero blocking bug, ngưỡng crash và sign-off.
- Feature flag và lịch phát hành riêng cho tính năng lớn là chiến lược giảm rủi ro chính.
- Rollout 1% → 100% giúp phát hiện sự cố trước khi ảnh hưởng diện rộng.
- Tỷ lệ phát hành thành công đạt khoảng 95% mỗi tuần ở quy mô 675 triệu người dùng.
Components of A Coding Agent
Sebastian Raschka phân tích cách các coding agent như Claude Code hay Codex CLI thực chất là một lớp framework phần mềm bao quanh LLM, giúp biến model thành công cụ lập trình hiệu quả. Chất lượng của agent không chỉ đến từ sức mạnh của model mà phần lớn phụ thuộc vào harness — tức vòng điều khiển, hạ tầng runtime và cách quản lý ngữ cảnh. Tác giả nhấn mạnh rằng một harness tốt có thể khiến cả reasoning model lẫn non-reasoning model trở nên mạnh hơn đáng kể so với khi dùng trực tiếp trong giao diện chat thông thường.
Bài viết đưa ra sáu thành phần cốt lõi của một coding agent: (1) Live repo context thu thập cấu trúc mã nguồn, trạng thái git và tài liệu dự án trước khi xử lý yêu cầu; (2) Prompt shape and cache reuse tách prompt thành phần ổn định (tool, instruction) và phần động để tái sử dụng cache; (3) Tool access and structured execution dùng danh sách tool được định nghĩa rõ cùng kiểm soát quyền thay vì để model tự do gợi ý; (4) Context reduction cắt output dài, khử trùng lặp và tóm tắt transcript cũ để tránh context bloat; (5) Structured session memory duy trì song song transcript đầy đủ và working memory gọn nhẹ để phục hồi session; (6) Bounded subagent cho phép agent chính ủy quyền subtask cho agent con với ngữ cảnh được kế thừa nhưng bị ràng buộc chặt.
Điểm chính:
- Chất lượng coding agent phần lớn đến từ harness, không chỉ từ bản thân model.
- Prompt caching và tách prompt ổn định/động giúp giảm chi phí tính toán đáng kể.
- Tool có cấu trúc với permission check đáng tin cậy hơn gợi ý dạng prose.
- Context reduction và working memory là bí quyết giữ session dài vẫn hiệu quả.
- Bounded subagent mở đường cho xử lý song song mà không mất kiểm soát.
Say the Thing You Want
Tác giả Terrible Software đưa ra một lời khuyên đơn giản nhưng thường bị bỏ qua trong môi trường làm việc: hãy nói thẳng với sếp về mục tiêu sự nghiệp thay vì giữ im lặng chờ đợi thời điểm phù hợp. Nhiều kỹ sư tránh đề cập đến tham vọng trong các buổi 1:1 vì sợ bị đánh giá là kiêu căng, chưa đủ năng lực hay sợ bị từ chối, nhưng chính sự im lặng đó khiến manager không có cơ sở để hỗ trợ. Câu nói đắt giá của bài viết: “một mong muốn mà bạn giữ cho riêng mình thì chẳng có bề mặt để tác động lên điều gì cả”.
Hai nhân viên cùng năng lực có thể đi đến kết quả rất khác nhau chỉ vì một người chịu nói ra nguyện vọng còn người kia thì không. Manager dù chu đáo đến đâu cũng không phải người đọc được suy nghĩ, và để đưa ra hướng dẫn có ý nghĩa hoặc phát hiện khoảng trống kỹ năng cần bổ sung, họ cần input trực tiếp từ chính bạn. Cách tiếp cận không cần cầu kỳ: chỉ cần hỏi thẳng về lộ trình lên senior hay điều kiện để được dẫn dắt một dự án là đủ để mở ra cuộc đối thoại. Nói ra mục tiêu giúp biến nó từ một giấc mơ thầm kín thành một cam kết rõ ràng mà cả hai bên có thể hành động cùng nhau.
Điểm chính:
- Mong muốn không được nói ra thì không có “bề mặt” để manager hỗ trợ.
- Sợ bị đánh giá hay từ chối là rào cản phổ biến khiến kỹ sư im lặng trong 1:1.
- Manager không đọc được suy nghĩ, họ cần input rõ ràng để phát hiện skill gap.
- Cùng năng lực, người lên tiếng thường tiến xa hơn người giữ im lặng.
- Một câu hỏi đơn giản về lộ trình senior đã đủ để mở đối thoại nghề nghiệp.
Agentic Coding and Microservices
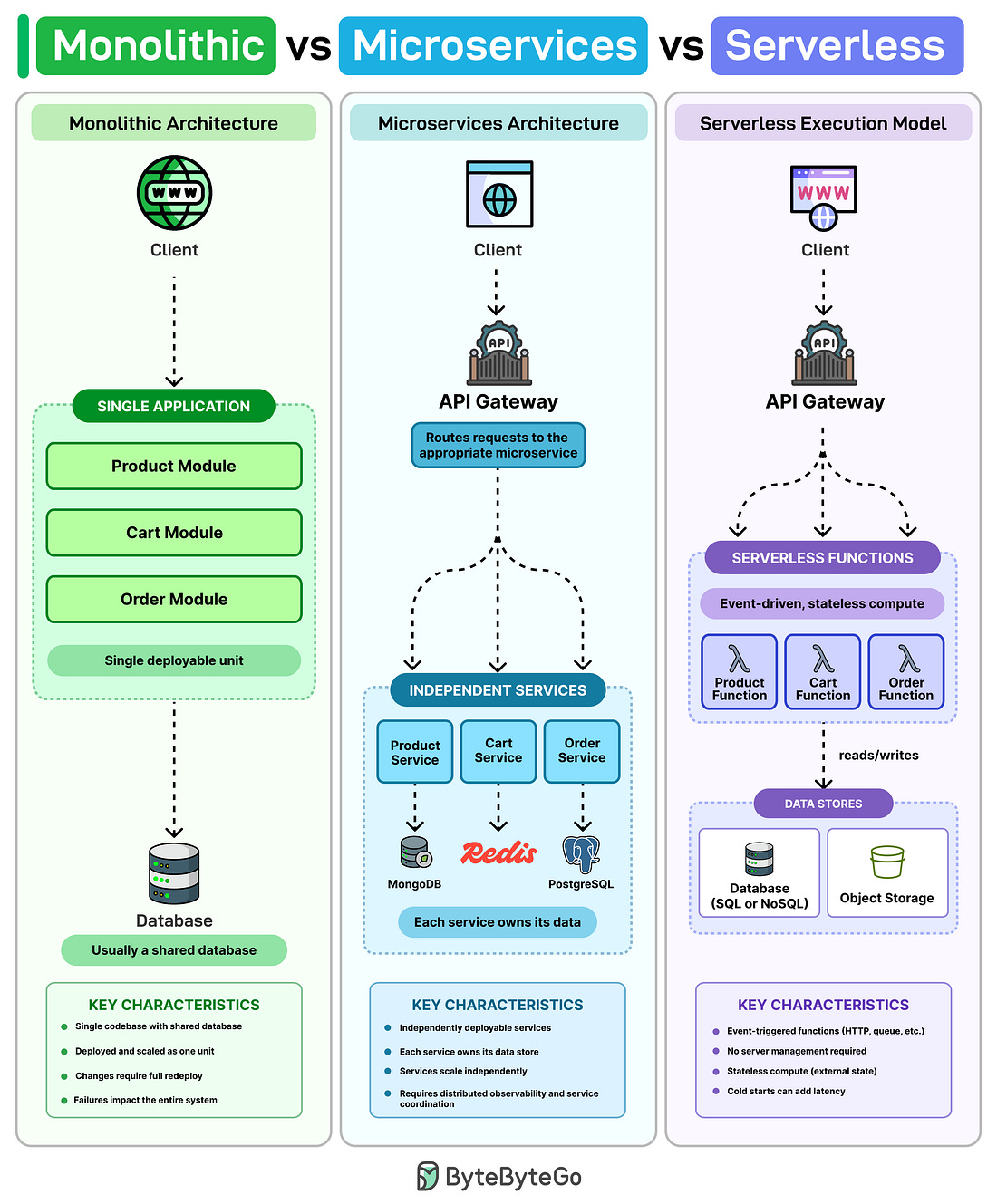
Nate Meyvis phản biện quan điểm phổ biến rằng LLM đang đẩy việc phát triển phần mềm hướng về microservices. Tác giả đồng ý rằng LLM làm việc hiệu quả hơn khi có sự đóng gói rõ ràng, nhưng nhấn mạnh nguyên tắc này không chỉ dành riêng cho AI. Microservices vẫn gặp nguyên vẹn các vấn đề kinh điển về chia sẻ dữ liệu giữa các service, và phát triển với AI thậm chí còn phơi bày sớm hơn những phụ thuộc chéo đó. Trong khi đó, monolith thường triển khai nhanh hơn, phù hợp với nhịp iteration cao khi có AI hỗ trợ.
Điểm quan trọng trong lập luận: đóng gói tốt không bắt buộc phải đi kèm với việc tách service. Một monolith có tài liệu rõ ràng và kỷ luật kiến trúc vẫn đạt được mức encapsulation cao. Trong thực tế, LLM có xu hướng mở rộng service sẵn có thay vì đề xuất service mới, nên việc định hướng kiến trúc bằng tài liệu — chẳng hạn một file AGENTS.md — thường đủ để giữ ranh giới chặt chẽ mà không phải gánh chi phí vận hành hệ phân tán. Thông điệp cuối cùng: khi phát triển nhanh cùng AI, monolith có tài liệu tốt thường là lựa chọn thực dụng hơn microservices.
Điểm chính:
- LLM cần encapsulation tốt nhưng không bắt buộc dẫn đến microservices.
- Vấn đề chia sẻ dữ liệu của microservices không biến mất khi có AI.
- Monolith thường triển khai nhanh hơn, hợp với nhịp iteration cao của AI-assisted.
- Tài liệu kiến trúc như AGENTS.md giúp enforce ranh giới trong monolith.
- Agent có xu hướng mở rộng service có sẵn hơn là đề xuất service mới.
Garbage Collection: From First Principles to Modern Collectors in Java, Go and Python
Bài viết đi từ nền tảng lý thuyết của garbage collection (GC) — bắt đầu với bài báo Lisp năm 1960 của McCarthy về mark-and-sweep — đến cách các ngôn ngữ hiện đại như Java, Go và Python thực thi GC. Taxonomy của Wilson năm 1992 chia GC thành ba trường phái: mark-and-sweep (đơn giản nhưng gây phân mảnh heap), copying/semi-space (đổi không gian lấy tốc độ cấp phát bằng cách di chuyển object giữa hai nửa heap), và reference counting (giải phóng ngay khi count về 0 nhưng gặp khó với chu trình). Giả thuyết thế hệ — “hầu hết object chết trẻ” — là cơ sở để các collector hiện đại tập trung thu gom vùng young generation, giảm công việc đáng kể.
Về cách hiện thực, Go dùng concurrent mark-and-sweep với tri-color marking và hybrid write barrier, nhắm tới pause dưới 1ms, không có compaction. Java G1GC chia heap thành region 1–32MB với vai trò động và dùng SATB cho concurrent marking; còn ZGC mã hóa metadata vào bit chưa dùng của pointer (colored pointer), dùng load barrier để cập nhật pointer lười, đạt pause sub-millisecond trên heap hàng trăm GB. CPython chủ yếu dựa vào reference counting với GIL bảo vệ, bổ sung cycle detector mark-and-sweep chạy theo thế hệ 0, 1, 2. Tác giả nhấn mạnh tradeoff cốt lõi: tracing chiếm ưu thế ở server runtime vì chi phí per-mutation của refcount tích lũy quá nhanh; compacting cho phép allocation dạng bump-pointer nhưng phải cập nhật pointer, còn non-compacting thì tránh được việc này nhưng chấp nhận cấp phát chậm hơn.
Điểm chính:
- Ba trường phái GC cổ điển: mark-and-sweep, copying, reference counting.
- Giả thuyết thế hệ giúp giảm đáng kể khối lượng công việc cho mỗi chu kỳ thu gom.
- Go dùng concurrent tri-color mark-and-sweep với hybrid write barrier, không compaction.
- Java ZGC đạt pause dưới 1ms trên heap hàng trăm GB nhờ colored pointer.
- Tracing chiếm ưu thế vì refcount có chi phí per-mutation quá cao ở nhịp allocation lớn.
I told Claude Code to build me an executive assistant
Obie Fernandez, CTO tại ZAR, chia sẻ cách anh biến Claude Code thành một trợ lý điều hành cá nhân chỉ bằng một prompt duy nhất: yêu cầu Claude tự thiết kế hệ thống markdown để hỗ trợ anh vận hành vai trò CTO ở đẳng cấp thế giới. Anh không tự tạo folder, không dựng template — chỉ để Claude tự tổ chức. Sau ba tuần, hệ thống đã xử lý 82 ghi chú cuộc họp, 47 cuộc họp trong tháng, theo dõi 23 thành viên team với 264 dòng context mỗi người, và tích lũy 11.579 dòng tri thức tổ chức, trong khi anh vẫn quản lý 10 kỹ sư, viết code và làm việc ở cấp C-level.
Điểm mấu chốt là anh “không bao giờ nghĩ về hệ thống” — chỉ nói chuyện tự nhiên với Claude, thường xuyên dùng giọng nói qua Wispr Flow và luôn mở ít nhất một session Claude Code trong ngày. Các lệnh thường gặp gồm “morning sync” để tổng hợp lịch và việc cần ưu tiên, “prep for 1:1 with Daniel” để đọc lịch sử và gợi ý chủ đề, “log decision about X” để tạo bản ghi quyết định có cấu trúc, hay “post this to #engineering on Slack”. Tích hợp Rube/MCP với Calendar, Slack, Twitter, Linear là yếu tố sống còn, cho phép Claude hành động trực tiếp mà không phải context switch. Thông điệp của Obie: mọi knowledge worker đều sẽ cần một hệ thống tương tự, ai chần chừ sẽ bị tụt lại khi đối thủ tích lũy lợi thế nhờ AI.
Điểm chính:
- Prompt khởi tạo đơn giản, để Claude tự thiết kế cấu trúc folder và template.
- Tích hợp Rube/MCP cho Calendar, Slack, Linear là điều kiện sống còn.
- Quy trình lặp lại: dán transcript cuộc họp, Claude tự tạo notes và action items.
- Chạy nhiều session song song để chuẩn bị nhiều meeting cùng lúc.
- “Không nghĩ về hệ thống” — Claude tự tổ chức, người dùng chỉ nói chuyện tự nhiên.
Bonus
Images:

Bài viết đã được review và cập nhật bởi Claude Code với Opus 4.7 (1M context).