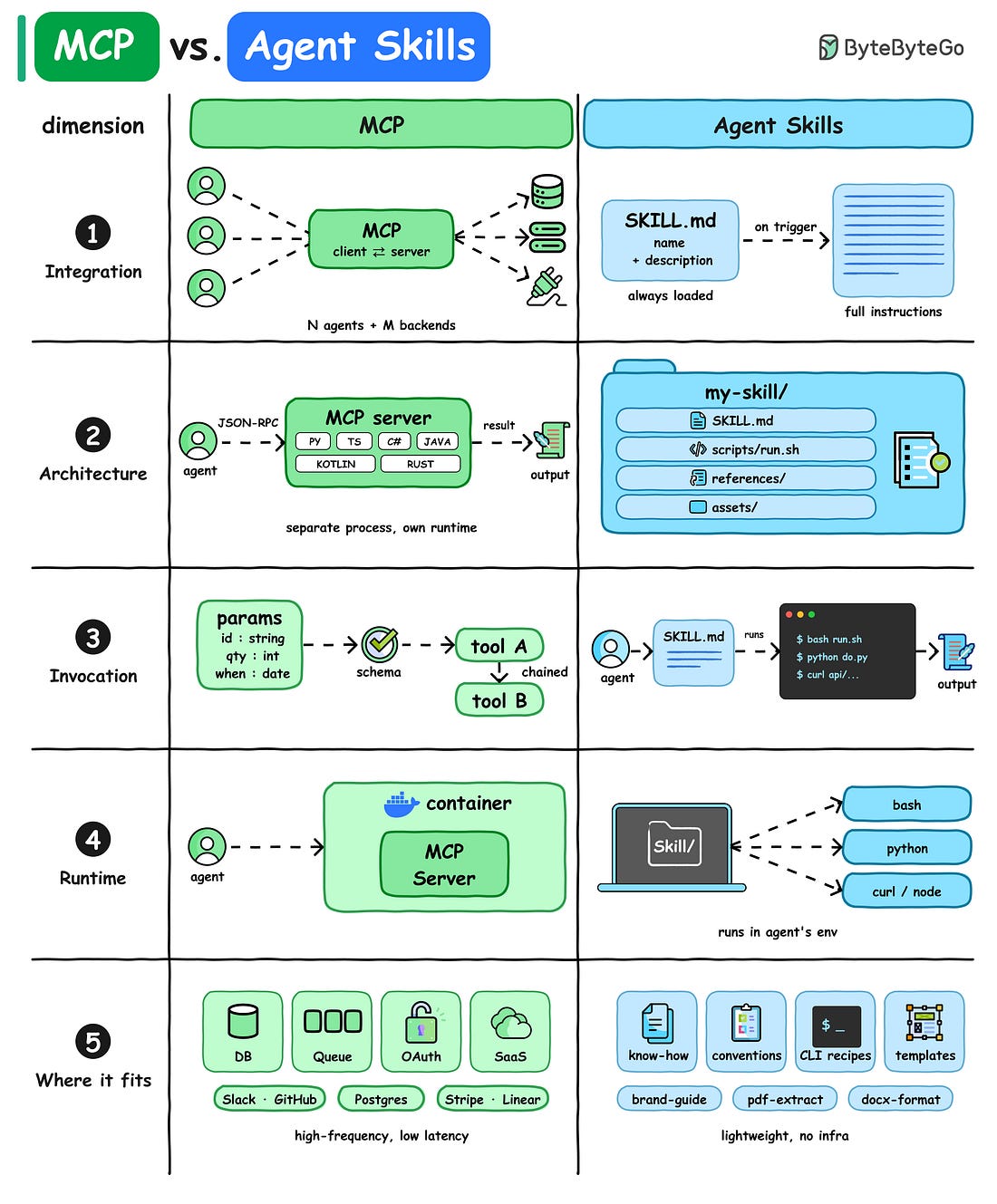
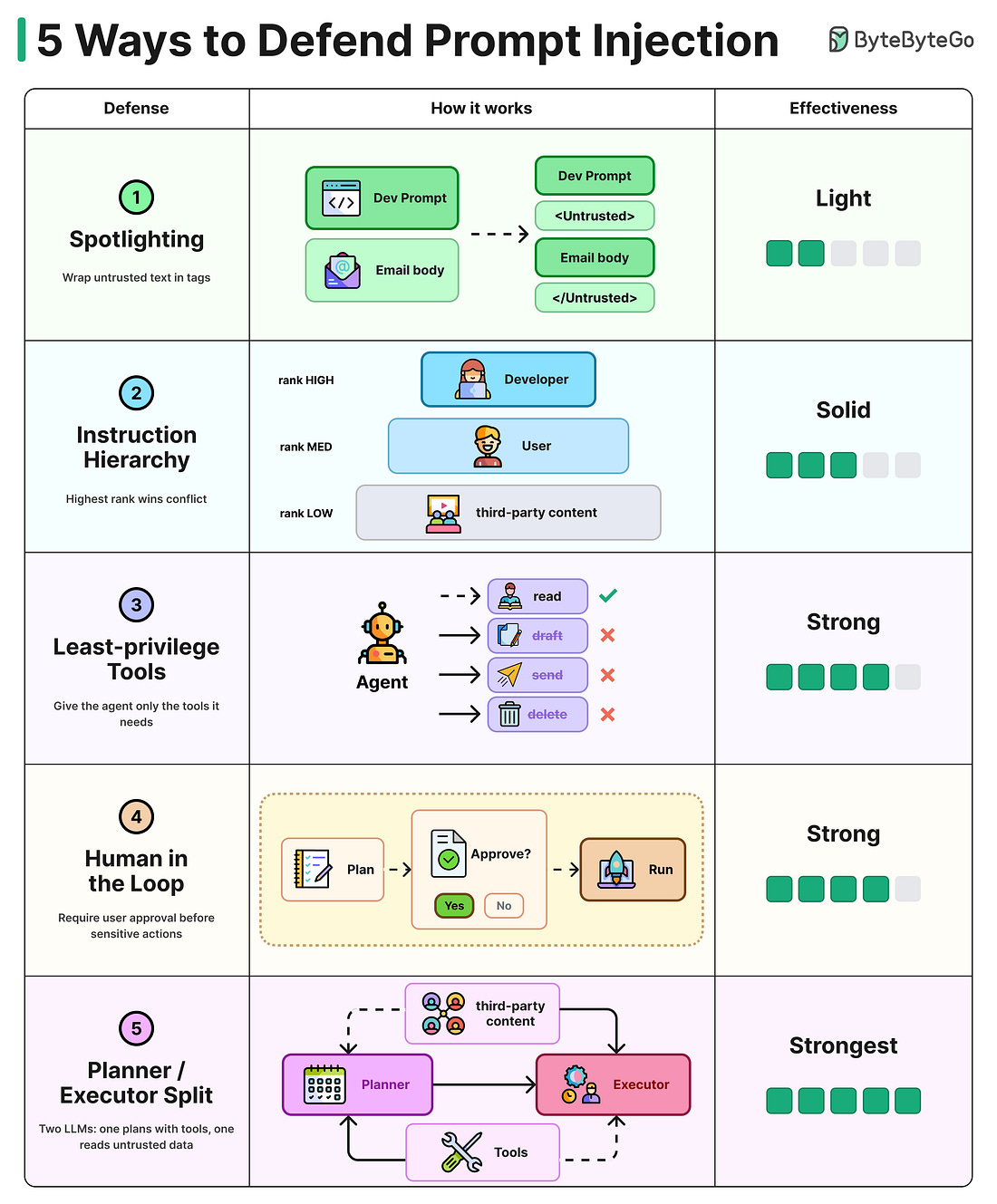
Mời bạn thưởng thức Newsletter #103.
Drunk Post: Things I’ve Learned as a Senior Engineer
Đây là bài viết được lưu giữ lại từ Reddit, nơi một kỹ sư dữ liệu giàu kinh nghiệm (hơn 10 năm trong nghề) chia sẻ những bài học nghề nghiệp một cách thẳng thắn và không kiêng dè. Bài viết được viết theo phong cách “hơi say” — nhưng những bài học bên trong thì hoàn toàn tỉnh táo và rất đáng suy ngẫm.
Tác giả nhận ra rằng việc chuyển công ty thường là cách hiệu quả nhất để thăng tiến sự nghiệp, thay vì chờ đợi được ghi nhận tại một nơi. Về mặt kỹ thuật, nắm vững 10–20 nguyên tắc cốt lõi quan trọng hơn là chạy theo từng công nghệ mới. Mã nguồn tốt là mã nguồn mà một kỹ sư junior có thể đọc hiểu được — không phải mã nguồn thể hiện sự phức tạp. Kỹ năng viết tài liệu và đề xuất giải pháp thường bị đánh giá thấp, nhưng lại là yếu tố quan trọng phân biệt kỹ sư senior và junior. Điều mang lại sự thỏa mãn sâu sắc nhất không phải là thành tích kỹ thuật cá nhân, mà là giúp đỡ người khác thành công.
Điểm chính:
- Thay đổi công ty thường là con đường nhanh nhất để phát triển sự nghiệp hơn là ở lại một chỗ
- Mã nguồn tốt là mã nguồn mà kỹ sư junior có thể hiểu — sự đơn giản mới là mục tiêu
- Kỹ năng viết tài liệu và đề xuất giải pháp bị đánh giá thấp nhưng lại rất quan trọng
- Kỹ sư senior biết khi nào nên phá vỡ các quy ước, không chỉ đơn thuần tuân theo chúng
- Giúp đỡ người khác thành công mang lại sự thỏa mãn sâu sắc hơn bất kỳ thành tích cá nhân nào
How I Use AI to Code
Chris Parsons lập luận rằng AI đang thay đổi căn bản cách lập trình — không phải theo nghĩa thay thế lập trình viên, mà là dịch chuyển trọng tâm công việc. Kỹ sư cấp cao giờ đây nên tập trung vào việc huấn luyện AI viết mã nguồn tốt hơn, thay vì dành thời gian review từng thay đổi thủ công. Vai trò đã chuyển từ “người phê duyệt” sang “người định hướng” — người định hình hành vi tương lai của hệ thống.
Tác giả khuyến nghị sử dụng Claude Code hoặc Codex CLI thay vì Copilot, với lý do “cái khung quan trọng hơn mô hình” — tức là cách cấu trúc context, chọn lọc thông tin và xây dựng vòng lặp agent mới là yếu tố then chốt. Để tận dụng tối đa AI, nhóm phát triển cần ba thành phần: hướng dẫn cố định trong tệp CLAUDE.md, các tệp skill để định hướng quy ước, và kho kiến thức di động dạng markdown. Chất lượng đầu ra phụ thuộc vào việc cân bằng context — quá ít thì kết quả chung chung, quá nhiều thì AI bị “chìm trong nhiễu”.
Điểm chính:
- Kỹ sư cấp cao nên huấn luyện AI thay vì review từng thay đổi thủ công
- “Cái khung quan trọng hơn mô hình” — cấu trúc context và vòng lặp agent mới là yếu tố cốt lõi
- Ba thành phần thực tế: hướng dẫn cố định (CLAUDE.md), tệp skill, và kho kiến thức di động
- Kiểm chứng kết quả đang trở thành nút thắt cổ chai mới, không phải tốc độ sinh mã nguồn
- Nhóm có quy trình CI/CD tốt từ trước sẽ có lợi thế lớn hơn khi áp dụng AI
Email is crazy
Email là một trong những công nghệ truyền thông thành công nhất lịch sử, nhưng bên dưới bề mặt đơn giản là một mê cung phức tạp đến khó tin. Sam Khawase dẫn dắt người đọc qua từng tầng của hệ thống email — từ lúc Alice nhấn “Gửi” đến khi Bob đọc được tin nhắn.
SMTP — giao thức nền tảng của email — được thiết kế vào thập niên 70 cho mạng học thuật ARPANET dựa trên sự tin tưởng, không phải bảo mật. Giao thức này cho phép địa chỉ phong bì (MAIL FROM) và địa chỉ hiển thị (From header) khác nhau — đây chính là lỗ hổng gốc rễ khiến phishing hoạt động được. Thay vì sửa SMTP, ngành công nghiệp đã vá víu bằng ba lớp xác thực: SPF (danh sách IP được phép gửi), DKIM (chữ ký mật mã), và DMARC (ràng buộc hai lớp trên và chỉ định hành động khi thất bại). Mỗi lớp giải quyết một vấn đề nhưng lại tạo ra vấn đề mới. Ngay cả khi vượt qua tất cả bộ lọc, email vẫn có thể bị chuyển vào thư rác mà không có bất kỳ thông báo nào — và điều này hoàn toàn hợp lệ theo chuẩn RFC.
Điểm chính:
- SMTP không kiểm tra sự khớp giữa địa chỉ phong bì và tiêu đề From — đây là gốc rễ của phishing
- Ba lớp bảo mật SPF, DKIM, DMARC được “vá” lên SMTP vì không thể thay thế giao thức lõi
- Email dùng “Opportunistic TLS” — nếu máy chủ nhận không hỗ trợ, kết nối rơi về văn bản thuần túy
- Máy chủ email có thể âm thầm chuyển thư vào spam mà không thông báo cho người gửi hay nhận
- Dù đầy lỗ hổng và vá víu, email vẫn xử lý hàng tỷ tin nhắn mỗi ngày một cách đáng tin cậy
High Performance Git
“High Performance Git” là tài nguyên học tập miễn phí của Ted Nyman, khám phá Git vượt xa công dụng thông thường là quản lý phiên bản. Thay vì dạy các lệnh Git cơ bản, tài liệu đi sâu vào kiến trúc bên trong: cơ sở dữ liệu đối tượng, cơ chế cache hệ thống tệp, và các giao thức truyền dữ liệu.
Nội dung đặc biệt hữu ích cho kỹ sư đang vận hành kho mã nguồn lớn (monorepo), cần tối ưu hiệu năng Git khi dự án phình to. Tài liệu gồm năm phần: khái niệm nền tảng (mô hình dữ liệu, refs, indexing), quản lý lịch sử và rewrite, tối ưu hóa lưu trữ cục bộ, vận hành kho mã nguồn quy mô lớn, và chẩn đoán sự cố. Toàn bộ nội dung được phát hành miễn phí dưới dạng PDF với giấy phép Creative Commons.
Điểm chính:
- Tập trung vào kiến trúc bên trong Git: packfiles, refs, object database — không chỉ dừng ở các lệnh thông thường
- Hướng dẫn thực tế cho monorepo: sparse checkout, partial clone, và chiến lược bảo trì kho mã nguồn
- Phù hợp với kỹ sư build, nhóm DevOps và bất kỳ ai cần hiểu sâu về Git ở quy mô lớn
- Miễn phí, phát hành dưới dạng PDF với giấy phép Creative Commons Attribution-ShareAlike 4.0
You can beat the binary search
Daniel Lemire giới thiệu thuật toán SIMD Quad — một phương pháp tìm kiếm lai giữa interpolation search bậc bốn (quaternary) và các lệnh SIMD (Single Instruction, Multiple Data) — áp dụng cho mảng số nguyên 16-bit đã sắp xếp. Thuật toán chia mảng thành các khối 16 phần tử cố định: dùng interpolation bậc bốn để thu hẹp phạm vi tìm kiếm trên ranh giới khối, rồi dùng SIMD (8 phép so sánh song song mỗi lần) để tìm phần tử chính xác bên trong khối.
Kết quả đo lường cho thấy SIMD Quad vượt trội so với tìm kiếm nhị phân trên mọi kịch bản: nhanh hơn hơn 2 lần trên Intel Emerald Rapids (cache lạnh). Điểm mấu chốt: các bộ vi xử lý hiện đại có khả năng song song hóa dữ liệu và bộ nhớ rất mạnh mà các thuật toán cổ điển chưa khai thác — và binary search là ví dụ điển hình cho điều đó.
Điểm chính:
- Thuật toán SIMD Quad kết hợp interpolation search bậc bốn với lệnh SIMD để tìm kiếm nhanh hơn binary search
- Nhanh hơn 2 lần trên Intel Emerald Rapids với cache lạnh; Apple M4 cũng cho thấy lợi thế đáng kể
- CPU hiện đại có nhiều tính năng song song mà thuật toán cổ điển chưa tận dụng
- Minh chứng rằng ngay cả với thuật toán kinh điển như binary search, vẫn còn dư địa cải thiện hiệu năng đáng kể
How might a browser be developed?
Paul Kinlan đặt ra câu hỏi thú vị: liệu AI có thể thay đổi căn bản cách trình duyệt web được xây dựng không? Trong tương lai gần, ông lập luận rằng các đặc tả chuẩn (specifications) kết hợp với bộ kiểm thử đơn vị toàn diện tạo ra “vùng an toàn” cho AI lập trình. Các tổ chức chuẩn hóa có thể tạo ra “trình duyệt tham chiếu chuẩn” để phát hiện lỗ hổng trong đặc tả, sau đó các nhà cung cấp sẽ dùng AI để triển khai tính năng dựa trên đặc tả đó.
Tầm nhìn dài hạn còn táo bạo hơn: trình duyệt có thể sinh ra các triển khai ngay tại thời điểm chạy (runtime) từ mô tả ý định, thay vì dựa vào các API được xây dựng sẵn. Điều này có thể loại bỏ sự cần thiết của các đặc tả như WebBluetooth nếu trình duyệt tự động tạo ra liên kết phần cứng từ tài liệu thiết bị hiện có. Tuy nhiên, đây cũng là điểm nghịch lý: trong khi việc sinh mã tức thời có thể cải thiện khả năng tiếp cận và đa ngôn ngữ theo mặc định, nó lại đe dọa cam kết cốt lõi của web — rằng cùng một URL mang lại trải nghiệm nhất quán trên mọi thiết bị và khu vực.
Điểm chính:
- AI có thể triển khai tính năng trình duyệt từ các đặc tả chuẩn được kiểm thử tốt — không cần lập trình thủ công từng tính năng
- Tổ chức chuẩn hóa có thể tạo “trình duyệt tham chiếu” bằng AI để phát hiện lỗ hổng trong đặc tả
- Tầm nhìn xa hơn: trình duyệt tự sinh triển khai tại runtime từ ý định, loại bỏ nhu cầu về API được xây dựng sẵn
- Rủi ro cốt lõi: tính nhất quán của trải nghiệm web có thể bị phá vỡ nếu mỗi thiết bị sinh mã khác nhau
- Ngành công nghiệp cần khám phá những khả năng này trước khi các tác nhân AI tự động định hình lại hạ tầng web
Agentic Coding is a Trap
Lars Faye đưa ra cảnh báo đáng suy ngẫm về xu hướng “agentic coding” — mô hình làm việc nơi AI thực hiện toàn bộ lập trình còn con người chỉ đóng vai “người điều phối”. Vấn đề cốt lõi là một nghịch lý: để giám sát AI hiệu quả, bạn cần kỹ năng lập trình sâu — nhưng chính việc dùng AI quá mức lại làm teo nhỏ những kỹ năng đó. Anthropic đã ghi nhận mức giảm 47% trong kỹ năng debug của lập trình viên khi dùng AI tích cực.
Faye cũng chỉ ra rằng AI đang tăng tốc đúng thứ chúng ta không cần: tốc độ sinh mã nguồn. Thứ chúng ta thực sự cần là hiểu sâu — và viết mã chính là quá trình tư duy, không phải chỉ là gõ phím. Thêm vào đó, sự phụ thuộc vào công cụ AI tạo ra “vendor lock-in” mới: khi Claude gặp sự cố, nhiều nhóm kỹ sư đã không thể làm việc được. Chi phí token không thể dự báo như lương nhân viên, tạo rủi ro tài chính khó kiểm soát.
Giải pháp tác giả đề xuất: dùng AI như công cụ phụ trợ, không phải người thay thế. Luôn tự mình lập trình từ 20–100% tùy nhiệm vụ, không sinh mã nguồn nhiều hơn mức có thể review trong một lần ngồi, và không nhờ AI làm thứ mình chưa bao giờ tự làm được.
Điểm chính:
- Nghịch lý giám sát AI: giám sát hiệu quả đòi hỏi kỹ năng lập trình, nhưng dùng AI quá mức làm teo nhỏ chính kỹ năng đó
- AI tăng tốc sai thứ — tốc độ sinh mã không phải vấn đề cần giải quyết, hiểu sâu mới là
- Phụ thuộc vào công cụ AI tạo ra “vendor lock-in” nguy hiểm: mất điện dịch vụ đồng nghĩa với tê liệt cả nhóm
- Không bao giờ sinh mã nhiều hơn mức có thể review kỹ trong một lần; không nhờ AI làm thứ bạn chưa từng tự làm
- Dùng AI như công cụ phụ trợ tư duy, không phải người thay thế tư duy
Be the Idiot
Bài viết của luminousmen đưa ra một lập luận đơn giản nhưng sâu sắc: đặt câu hỏi làm rõ — dù trông có vẻ ngây ngô — là kỹ năng chuyên nghiệp quan trọng, không phải điểm yếu. Tác giả lấy ví dụ từ giao thức truyền thông quân sự: phi công luôn đọc lại lệnh để xác nhận hiểu đúng, không phải vì họ kém, mà vì sự rõ ràng quan trọng hơn việc trông có vẻ thông minh.
Hai nguyên tắc cốt lõi để giao tiếp rõ ràng trong kỹ thuật: (1) Lặp lại thông tin quan trọng qua nhiều kênh — types, tài liệu, tham số tường minh — để tránh hiểu nhầm; (2) Dùng từ ngữ cụ thể thay vì mơ hồ (timeout_seconds: 30 rõ hơn nhiều so với timeout: short). Bốn câu hỏi mà tác giả gọi là “ngốc” nhưng đã ngăn chặn nhiều thảm họa: Điều gì xảy ra khi nó thất bại? Làm sao biết nó đang hoạt động đúng? “Xong” trông như thế nào? Bạn có thể cho xem ví dụ không? Điều mấu chốt: đặt câu hỏi sẽ hiệu quả hơn khi được framing là “tôi đang thiếu context” thay vì “mọi người đang sai”.
Điểm chính:
- Đặt câu hỏi làm rõ là kỹ năng chuyên nghiệp, không phải điểm yếu — giao thức quân sự ưu tiên sự rõ ràng hơn vẻ thông minh
- Lặp lại thông tin quan trọng qua nhiều kênh (types, tài liệu, tham số) để phòng ngừa hiểu nhầm
- Dùng từ ngữ cụ thể và có thể đo lường thay vì ngôn ngữ mơ hồ
- Bốn câu hỏi quan trọng nhất: thất bại thì sao, biết hoạt động đúng bằng cách nào, “xong” nghĩa là gì, có ví dụ không
- Chi phí duy nhất đắt hơn việc trông ngốc là ship sai sản phẩm vì không ai dám hỏi
3 constraints before I build anything
Jordan Lord chia sẻ ba ràng buộc (constraints) mà anh áp dụng trước khi xây dựng bất kỳ sản phẩm nào, đúc kết từ 10 năm kinh nghiệm. Quan điểm cốt lõi: ràng buộc không phải rào cản sáng tạo — mà là chất xúc tác, giúp thu hẹp khả năng và buộc bạn tập trung vào điều thực sự quan trọng. Minecraft (khối vuông), IKEA (đóng gói phẳng), Kubernetes đều là minh chứng cho việc ràng buộc tạo ra sản phẩm xuất sắc.
Ba ràng buộc cụ thể: (1) Một trang hoặc không xây dựng — ý tưởng phải vừa trong một trang, buộc bạn làm rõ tư duy trước khi động tay lập trình; (2) Công nghệ lõi phải tách rời khỏi sản phẩm — xây dựng tài sản trí tuệ có thể tái sử dụng độc lập với hướng đi của sản phẩm, tạo ra giá trị tích lũy dài hạn; (3) Một ràng buộc định nghĩa phải định hình sản phẩm — chọn một ràng buộc rõ ràng làm bản sắc sản phẩm, ngăn chặn feature creep bằng cách thu hẹp các quyết định thiết kế.
Điểm chính:
- Ràng buộc là chất xúc tác sáng tạo, không phải rào cản — chúng buộc bạn tập trung vào điều cốt lõi
- Quy tắc một trang: nếu ý tưởng không vừa một trang, nó chưa đủ rõ để xây dựng
- Công nghệ lõi nên có thể tái sử dụng độc lập với sản phẩm để tạo giá trị tích lũy lâu dài
- Một ràng buộc định nghĩa giúp sản phẩm có bản sắc và ngăn chặn feature creep hiệu quả
- Bất kỳ ý tưởng nào không vượt qua ba ràng buộc này đơn giản là không được xây dựng
Swissing a Table
Phil Pearl giải thích cách Swiss tables — một thiết kế hash table hiện đại — hoạt động từ bên trong và tại sao chúng vượt trội hơn các triển khai thông thường ở quy mô lớn. Ý tưởng cốt lõi: thay vì lưu từng phần tử riêng lẻ, Swiss tables nhóm 8 cặp key-value vào một “group”, kết hợp với “control bytes” chứa metadata — bit cao nhất đánh dấu slot trống, 7 bit thấp hơn lưu một phần giá trị hash. Nhờ đó, các phép kiểm tra có thể xử lý song song nhiều slot cùng lúc bằng thao tác bitwise, thay vì kiểm tra từng ô một.
Kết quả đo lường cho thấy Swiss tables không phải lúc nào cũng nhanh hơn: với bảng nhỏ (10–4000 phần tử), cách tiếp cận đơn giản vẫn nhanh hơn 15–36%. Nhưng khi bảng đầy (32.768 phần tử), Swiss tables nhanh hơn đến 71,65%. Quan trọng hơn, chúng có thể hoạt động hiệu quả ở hệ số tải cao hơn — nghĩa là tiết kiệm bộ nhớ đáng kể so với hash table truyền thống.
Điểm chính:
- Swiss tables nhóm 8 phần tử mỗi “group” và dùng control bytes để kiểm tra nhiều slot song song bằng bitwise
- Với bảng nhỏ, cách tiếp cận đơn giản vẫn nhanh hơn 15–36%; Swiss tables chỉ vượt trội ở quy mô lớn
- Bảng đầy (32.768 phần tử): Swiss tables nhanh hơn đến 71,65%
- Lợi thế quan trọng nhất: hoạt động tốt ở hệ số tải cao hơn, tiết kiệm bộ nhớ đáng kể
- Tương lai: có thể tăng tốc thêm với SIMD, nhưng triển khai Go hiện tại còn hạn chế trên ARM
The AI engineering stack we built internally — on the platform we ship
Cloudflare chia sẻ chi tiết hạ tầng AI nội bộ mà họ xây dựng — hoàn toàn trên chính các sản phẩm họ cung cấp cho khách hàng. Hệ thống phục vụ khoảng 3.683 người dùng nội bộ (93% bộ phận R&D), xử lý 20 triệu yêu cầu AI Gateway và 241 tỷ token mỗi tháng.
Kiến trúc gồm ba tầng: tầng nền tảng (Cloudflare Access xử lý xác thực zero-trust, AI Gateway theo dõi chi phí và kiểm soát dữ liệu, Workers AI chạy mô hình mã nguồn mở với chi phí thấp hơn đáng kể so với các mô hình độc quyền); tầng tri thức (Backstage theo dõi 2.055 dịch vụ nội bộ, file AGENTS.md tự động sinh cho từng kho mã nguồn chứa quy ước và ranh giới cụ thể); và tầng thực thi (AI Code Reviewer tự động đánh giá mọi merge request, phân loại mức rủi ro và chuyển cho các agent chuyên biệt về bảo mật, chất lượng và tuân thủ). Điểm đáng học: người dùng chỉ cần xác thực một lần, một proxy Worker tự động inject thông tin xác thực cho mọi yêu cầu LLM tiếp theo.
Điểm chính:
- Toàn bộ hạ tầng AI nội bộ chạy trên chính sản phẩm Cloudflare — “ăn đồ mình nấu”
- AI Gateway tập trung theo dõi chi phí và kiểm soát dữ liệu cho 20 triệu yêu cầu/tháng
- File AGENTS.md tự động sinh cho từng kho mã nguồn cung cấp context và quy ước cho AI
- AI Code Reviewer tự động đánh giá mọi merge request và phân luồng đến agent chuyên biệt
- Đơn giản hóa qua tập trung hóa: xác thực một lần, proxy tự động xử lý phần còn lại
Bonus
Images: